
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- bias
- Convolution Neural Network
- 데이터크롤링
- kt에이블스쿨
- 뉴스웨일
- MaxPooling2D
- NewsWhale
- AI
- Neural Network
- pandas
- fashion mnist
- Pooling Layer
- 키워드 기반 뉴스 조회
- 모델평가
- 데이터분석
- AWS 입문자를 위한 강의
- 딥러닝
- OneHotEncoding
- 머신러닝
- 데이터처리
- 데이터
- CNN 실습
- explained AI
- CIFAR-10
- CNN
- 인공지능
- plot_model
- learning_rate
- 크롤링
- CRISP-DM
- Today
- Total
jjinyeok 성장일지
데이터 처리 #1 - 2022/08/08~2022/08/09 본문
아직 모델링 과정보다 데이터 처리와 데이터 분석에 중점으로 수업이 진행되고 있는데 8월 8일부터 9일까지는 데이터 처리에 대한 강의가 진행되었다. 멋쟁이사자처럼 해커톤을 준비하며 조금씩 밀렸지만 연휴를 기점으로 다시 정리하는 시간을 가져보고자 한다.
1. CRISP-DM
CRISP-DM은 Cross-industry standard process for data mining의 준말로 전 세계에서 가장 많이 사용되는 데이터 마이닝 표준 방법론이라고 한다. 에이블스쿨에서 가장 많이 본 그림이자 많이 볼 그림이 될 것 같다. CRISP-DM에 대해서는 8월 10일에 더 진하게 다루었었기 때문에 8월 10일차 강의를 정리할 때 다시 정리하도록 하겠다. 이번 강의의 목표는 CRISP-DM에서 Data Preparation이었다. 이전 판다스와 크롤링을 통해 데이터를 이해하고 수집하는 과정을 배웠는데 이러한 데이터를 모델링 구조에 맞추어 변형시키는 작업이 Data Preparation이다.

2. 데이터 결합하기
먼저 두 데이터프레임 혹은 시리즈를 결합하는 방법으로 pandas의 merge() 메서드가 있다. 이것은 기존 SQL의 JOIN문법과 비슷하다. A라는 데이터프레임과 B라는 데이터프레임을 merge로 결합하는 문법은 pd.merge(a_dataframe, b_dataframe, how={}, on={})이다. pd.merge 메서드의 1번째, 2번째 parameter는 합치고자하는 데이터프레임 혹은 시리즈이다. how와 on이 중요한데 on은 어떤 컬럼을 기준으로 결합할지 선택하는 것이고 how는 어떤 방식으로 결합하는지 선택하는 것이다. 방식은 다음과 같다.
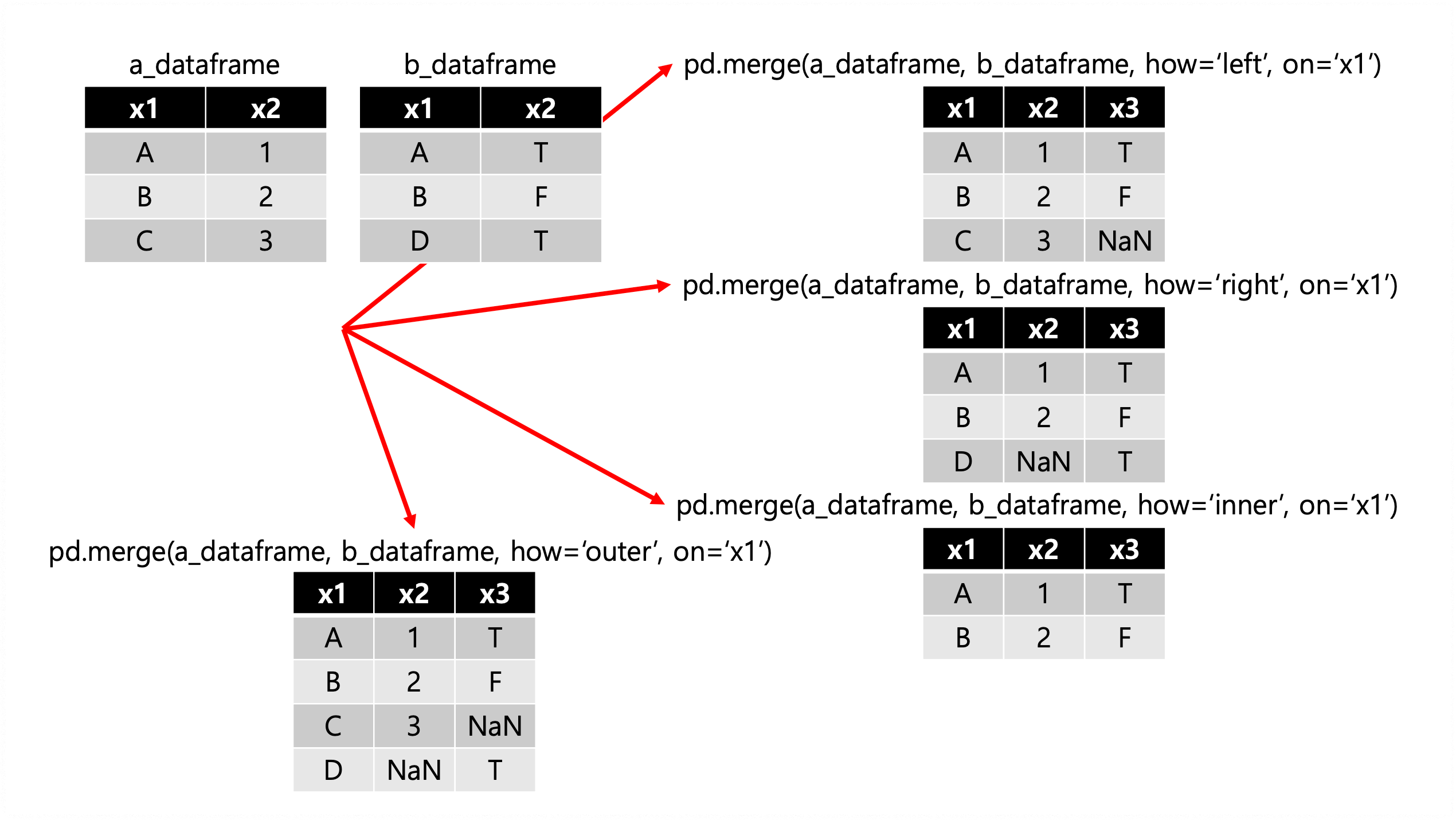
이때 how의 default 값은 inner이고 on으로 칼럼명을 지정하지 않는다면 자동으로 key를 잡아준다. 두 데이터프레임 혹은 시리즈가 연관이 있을때 pandas의 merge() 메서드를 사용하여 두 데이터를 결합하고 데이터 인사이트를 찾을 수 있다.
3. 데이터 합치기
여러 데이터프레임 합치는 방법으로 pandas의 concat() 메서드가 있다. 이때 concat은 어떠한 기준으로 결합을 하는 것이 아닌 말 그대로 데이터프레임 여러 개를 이어 붙이는 작업이다. 이때 데이터를 행으로 붙이는 방법과 열로 붙이는 방법이 존재한다. 어떤 방법을 선택할지는 axis parameter를 통해 결정하고 axis=0이면 행으로 axis=1이면 열로 데이터를 합친다. default 값은 axis=0으로 행으로 데이터를 합친다. 과정은 다음과 같다.
# a_dataframe과 b_dataframe 확인 작업
print(a_dataframe.head())
print('-' * 25)
print(b_dataframe.head())
# Category Amt
# 0 간식 12920570
# 1 과일 49789339
# 2 반찬류 32204820
# 3 유제품 45261956
# 4 채소 54822783
# -------------------------
# Category Qty
# 0 간식 12130
# 1 과일 6786
# 2 반찬류 20210
# 3 유제품 19731
# 4 채소 27859
# 행으로 합치기 -> 위아래로 붙이기 (default)
print(pd.concat([a_dataframe, b_dataframe]))
# Category Amt Qty
# 0 간식 12920570.0 NaN
# 1 과일 49789339.0 NaN
# 2 반찬류 32204820.0 NaN
# 3 유제품 45261956.0 NaN
# 4 채소 54822783.0 NaN
# 0 간식 NaN 12130.0
# 1 과일 NaN 6786.0
# 2 반찬류 NaN 20210.0
# 3 유제품 NaN 19731.0
# 4 채소 NaN 27859.0
# 열로 합치기 -> 옆으로 붙이기
print(pd.concat([data2, data3], axis=1))
# Category Amt Category Qty
# 0 간식 12920570 간식 12130
# 1 과일 49789339 과일 6786
# 2 반찬류 32204820 반찬류 20210
# 3 유제품 45261956 유제품 19731
# 4 채소 54822783 채소 27859
4. rolling & shift
행과 행 사이에 시간 순서가 있는 데이터를 시계열 데이터라고 한다. 시계열 데이터를 이용해 날씨나 주가 등 예측 모델을 만드는 것이 가능하다. 시계열 데이터에 대해 rolling() 메서드과 shift() 메서드를 통해 데이터의 이동평균값을 구하거나 행을 이동시키는 등의 일이 가능하다. 어떠한 기업의 종가와 거래량 정보 데이터프레임을 예시로 rolling() 메서드와 shift() 메서드를 정리하도록 하겠다. 먼저 rolling() 메서드 같은 경우는 parameter로 행 데이터를 몇개씩 묶을지를 입력받는다. 이후 max, mean 등과 같은 집계함수를 이용하여 묶은 데이터를 집계하는 역할을 한다. 과정은 다음과 같다.
import pandas as pd
# 데이터 확인하기
print(stock.head())
# Date Close Volume
# 0 2016-01-04 234500.0 173905.0
# 1 2016-01-05 241000.0 182985.0
# 2 2016-01-06 239000.0 108574.0
# 3 2016-01-07 240500.0 113376.0
# 4 2016-01-08 241500.0 81557.0
# 3일치 이동 평균값 구하기
stock['Close_Moving_Average_3'] = stock['Close'].rolling(3).mean()
print(stock.head())
# Date Close Volume Close_Moving_Average_3
# 0 2016-01-04 234500.0 173905.0 NaN
# 1 2016-01-05 241000.0 182985.0 NaN
# 2 2016-01-06 239000.0 108574.0 238166.666667
# 3 2016-01-07 240500.0 113376.0 240166.666667
# 4 2016-01-08 241500.0 81557.0 240333.333333그림으로 본다면 더 자세한데 그림은 다음과 같다. 즉 3일치 시리즈의 이전 행 데이터들을 묶고 stock['Close'].rolling(3) 평균 집계하여 mean() 이동 평균값을 구한다.
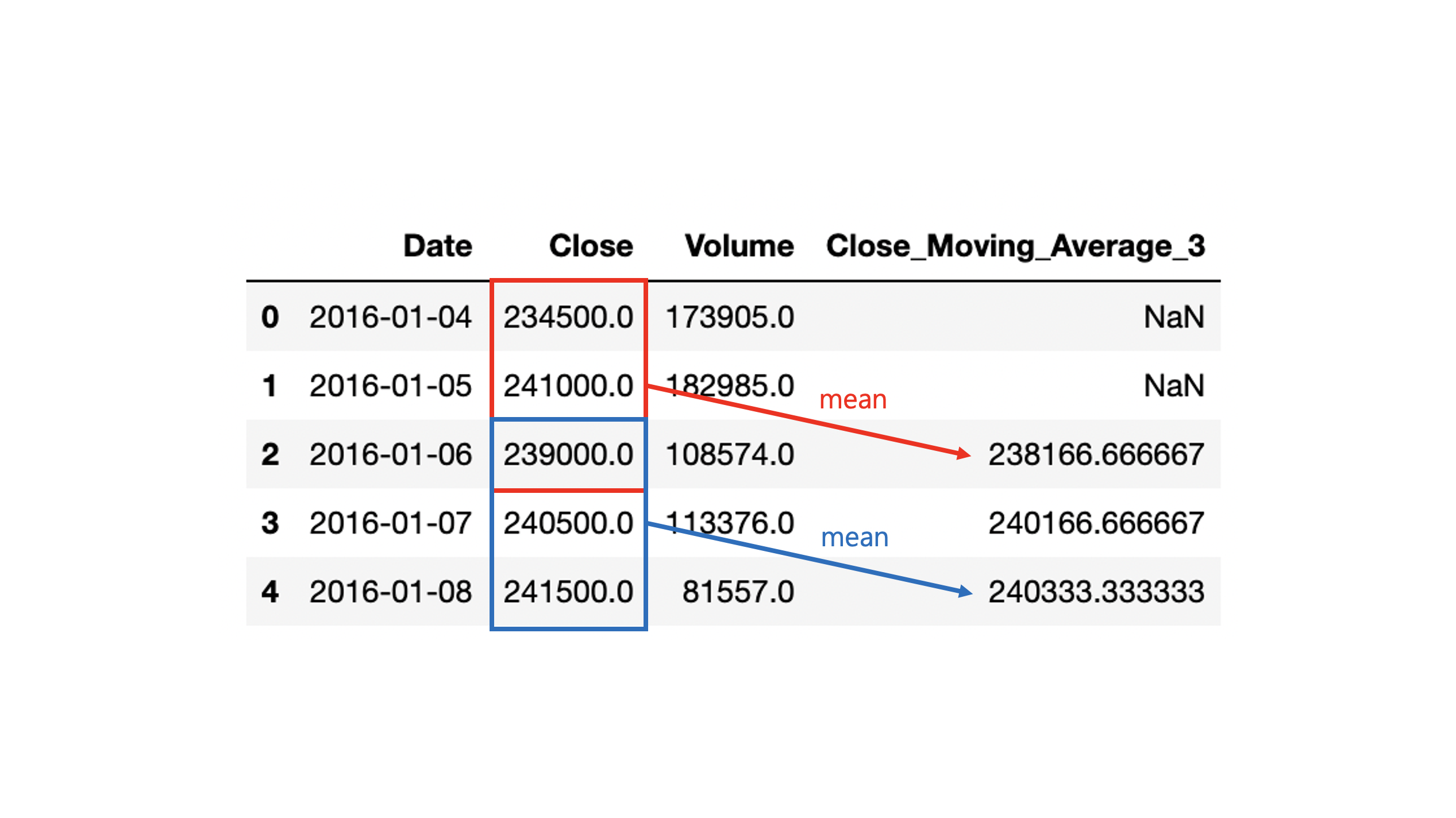
이때 묶을 이전 행 데이터가 없는 경우 기본적으로 NaN 처리를 진행한다. NaN처리를 방지하기 위해 rolling() 메서드 내부에는 min_periods라는 parameter가 존재한다. min_periods parameter는 기본적인 묶음 단위보다 이전의 데이터양이 적어 NaN 처리를 할 때 NaN 처리 대신 min_periods 길이만큼 행 데이터를 묶는다. 과정은 다음과 같다.
stock['Close_MA_3_MP_1'] = stock['Close'].rolling(3, min_periods=1).mean()
print(stock.head())
# Date Close Volume Close_Moving_Average_3 Close_MA_3_MP_1
# 0 2016-01-04 234500.0 173905.0 NaN 234500.000000
# 1 2016-01-05 241000.0 182985.0 NaN 237750.000000
# 2 2016-01-06 239000.0 108574.0 238166.666667 238166.666667
# 3 2016-01-07 240500.0 113376.0 240166.666667 240166.666667
# 4 2016-01-08 241500.0 81557.0 240333.333333 240333.333333마찬가지로 그림으로 보면 더 자세한데 그림은 다음과 같다. 3일치 시리즈의 이전 행 데이터들을 묶을 때 stock['Close'].rolling(3) 첫번째 두번째 데이터들이 묶이지 않아 NaN 처리를 하는 대신 min_periods에 해당하는 묶음 단위인 1로 stock['Close'].rolling(3, min_periods=1) 다시 묶어 평균 집계 mean() 하여 이동 평균값을 구한다.
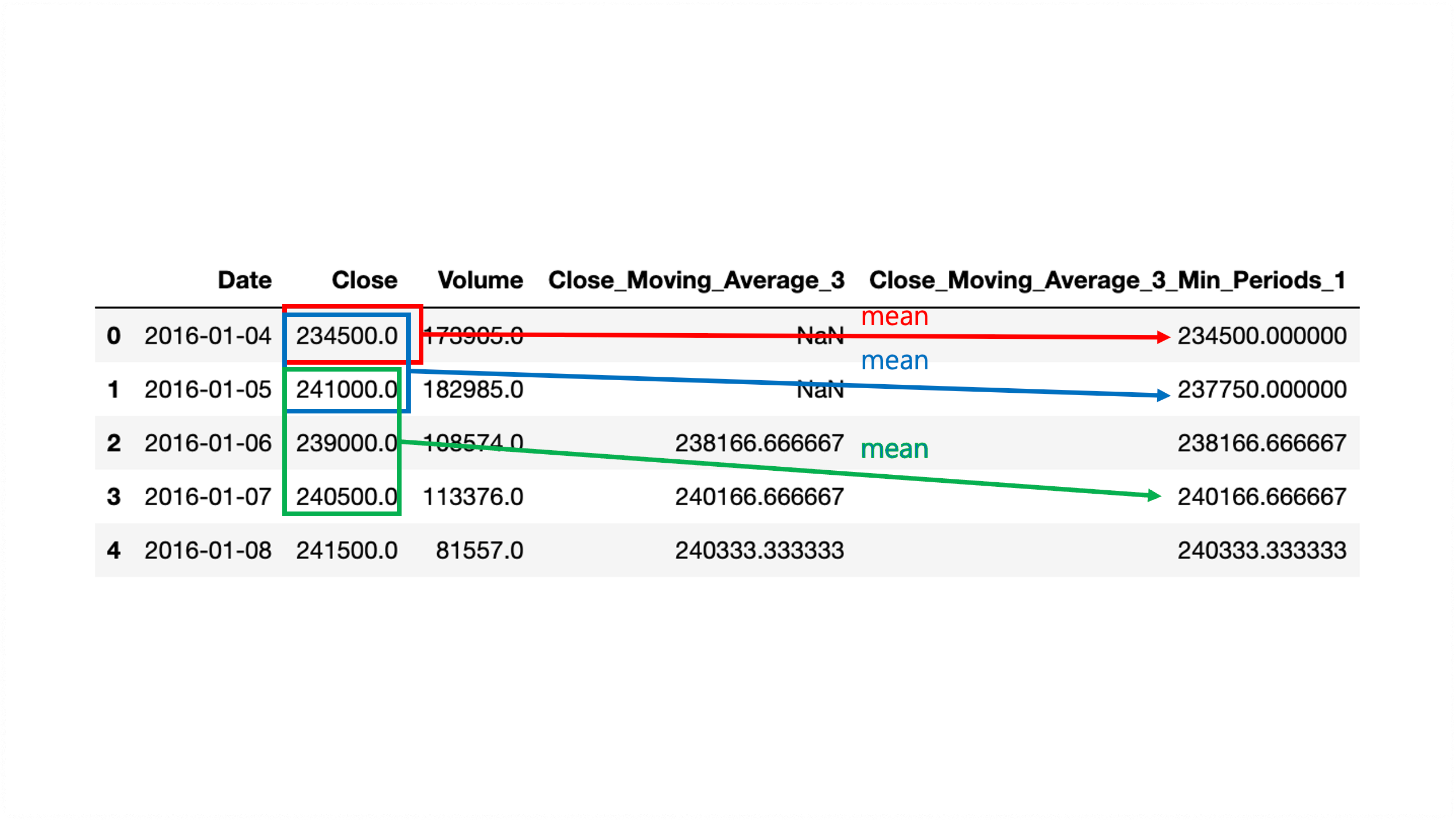
shift() 메서드는 행을 이동시키는 메서드이다. default 값은 1이며 함수 내부에 입력한 숫자만큼 행이 이동한다. 과정은 다음과 같다. 이런식으로 shift() 메서드를 통해 행을 이동시켰을 때 Close_MA_3_lag1 열이 의미하는 것은 전날까지의 3일치의 데이터 이동 평균값이 된다.
stock['Close_MA_3_lag1'] = stock['Close_Moving_Average_3'].shift() # shift()안에 숫자를 변경해 보며 기능을 알아보자. default = 1
print(stock.head(5))
# Date Close Volume Close_Moving_Average_3 Close_MA_3_MP_1 \
# 0 2016-01-04 234500.0 173905.0 NaN 234500.000000
# 1 2016-01-05 241000.0 182985.0 NaN 237750.000000
# 2 2016-01-06 239000.0 108574.0 238166.666667 238166.666667
# 3 2016-01-07 240500.0 113376.0 240166.666667 240166.666667
# 4 2016-01-08 241500.0 81557.0 240333.333333 240333.333333
#
# Close_MA_3_lag1
# 0 NaN
# 1 NaN
# 2 NaN
# 3 238166.666667
# 4 240166.666667이와 같이 rolling과 shift를 사용해서 시계열 데이터로부터 인사이트를 발견할 수 있다.
5. 시계열 데이터 사용하기
시계열 데이터를 사용하기 위해 rolling과 shift뿐만이 아니라 날짜 요소를 뽑는 방법과 데이터 증감을 확인할 수 있는 메서드를 추가적으로 정리하고자 한다. 먼저 csv 파일 형식으로 날짜 데이터를 받아올 때는 string 형식으로 받아오게 된다. 이러한 데이터에서 날짜 요소를 뽑기 위해서는 pandas의 to_datetime() 메서드를 이용한다. 과정은 다음과 같다.
# 기존 데이터
# date열의 데이터타입이 object 즉 string임을 확인할 수 있다.
print(data.info())
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 1095 entries, 0 to 1094
# Data columns (total 2 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 date 1095 non-null object
# 1 sales 1095 non-null int64
# dtypes: int64(1), object(1)
# memory usage: 17.2+ KB
# None
# pandas의 to_datetime() 메서드를 이용하여 데이터타입을 바꿔준 데이터
# date열의 데이터타입이 datetime64[ns]로 변경되었음을 확인할 수 있다.
data['date'] = pd.to_datetime(data['date'])
print(data.info())
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 1095 entries, 0 to 1094
# Data columns (total 2 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 date 1095 non-null datetime64[ns]
# 1 sales 1095 non-null int64
# dtypes: datetime64[ns](1), int64(1)
# memory usage: 17.2 KB
# None데이터 타입을 변경한 이후 날짜 데이터를 뽑는 과정은 다음의 표를 이용하여 뽑아낼 수 있다.
| 메서드 | 반환값 |
| data['date'].dt.date | YYYY-MM-DD(문자) |
| data['date'].dt.year | 연(4자리숫자) |
| data['date'].dt.month | 월(숫자) |
| data['date'].dt.month_name() | 월(문자) |
| data['date'].dt.day | 일(숫자) |
| data['date'].dt.time | HH:MM:SS(문자) |
| data['date'].dt.hour | 시(숫자) |
| data['date'].dt.minute | 분(숫자) |
| data['date'].dt.second | 초(숫자) |
| data['date'].dt.quarter | 분기(숫자) |
| data['date'].dt.day_name() | 요일이름(문자) |
| data['date'].dt.weekday | 요일숫자(0-월, 1-화) (=dayofweek) |
| data['date'].dt.weekofyear | 연 기준 몇주째(숫자) (=week) |
| data['date'].dt.dayofyear | 연 기준 몇일째(숫자) |
| data['date'].dt.days_in_month | 월 일수(숫자) (=daysinmonth) |
시계열 데이터프레임에서 diff() 메서드를 사용하여 특정 시점 대비 증감 또한 알 수 있다. shift() 메서드와 마찬가지로 default 값은 1이며 diff() 메서드를 사용함으로써 전날치 증감량 등을 확인할 수 있다. 과정은 다음과 같다.
print(data.head())
# date sales
# 0 2013-01-01 43
# 1 2013-01-02 57
# 2 2013-01-03 45
# 3 2013-01-04 45
# 4 2013-01-05 55
# 전일대비 증감
data['Diff1'] = data['sales'].diff()
# 2일 전 대비 증가
data['Diff2'] = data['sales'].diff(2)
print(data.head())
# date sales Diff1 Diff2
# 0 2013-01-01 43 NaN NaN
# 1 2013-01-02 57 14.0 NaN
# 2 2013-01-03 45 -12.0 2.0
# 3 2013-01-04 45 0.0 -12.0
# 4 2013-01-05 55 10.0 10.0
'[KT AIVLE School]' 카테고리의 다른 글
| 데이터 분석 및 의미 찾기 #1 - 2022/08/10~2022/08/12 (0) | 2022.08.15 |
|---|---|
| 데이터 처리 #2 - 2022/08/08~2022/08/09 (0) | 2022.08.15 |
| 웹크롤링 # 4 Selenium - 2022/08/03~2022/08/05 (0) | 2022.08.14 |
| 웹크롤링 # 3 정적 페이지 크롤링 - 2022/08/03~2022/08/05 (0) | 2022.08.08 |
| 웹크롤링 # 2 Open API - 2022/08/03~2022/08/05 (0) | 2022.08.08 |



