
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- AWS 입문자를 위한 강의
- 모델평가
- 인공지능
- OneHotEncoding
- Pooling Layer
- 데이터
- CNN 실습
- fashion mnist
- NewsWhale
- 크롤링
- 키워드 기반 뉴스 조회
- plot_model
- CIFAR-10
- 딥러닝
- kt에이블스쿨
- pandas
- explained AI
- Neural Network
- bias
- MaxPooling2D
- learning_rate
- AI
- 데이터분석
- CRISP-DM
- 데이터크롤링
- 데이터처리
- CNN
- 뉴스웨일
- Convolution Neural Network
- 머신러닝
- Today
- Total
jjinyeok 성장일지
Python 라이브러리 # 1 NumPy - 2022/08/01~2022/08/02 본문
에이블스쿨에서 세번째 수업으로 8월 1일부터 8월 2일까지 <Python 라이브러리 활용> 수업이 진행되었다. (두번째 수업이었던 <Python 프로그래밍> 수업은 크게 새롭거나 어려운 내용이 없어 정리하지 않았다.) 수업에서 인공지능 개발에 필수적인 numpy, pandas, matplotlib 라이브러리에 대해 공부하였다.
1. 데이터를 통한 문제 해결
AI 개발을 비롯하여 데이터를 통한 문제 해결의 큰 그림은 ¹⁾어떤 문제를 해결하기 위해 (Business Understanding) ²⁾어떤 데이터를 사용하고 (Data Understanding) ³⁾데이터를 어떻게 준비하여 (Data Preparation) ⁴⁾모델링하고 (Modeling) ⁵⁾평가하여 (Evaluation) ⁶⁾배포하는 (Deployment) 것이다.
2. 데이터 분류
과정 속 핵심은 데이터이다. 따라서 데이터가 어떻게 분류되는지 아는 것은 AI 개발의 기본이다.

범주형 데이터는 어떠한 범주로 묶을 수 있는 정성적 데이터를 의미한다. 범주형 데이터 중 명목형 데이터는 명목적인 값으로 범주가 묶이는 것이다. 범주형 데이터 중 순서형 데이터는 숫자를 범주로 잘라낸 것을 의미한다. 이때 월과 같은 데이터는 범주형 데이터에 속하는지 수치형 데이터에 속하는지 헷갈릴 수 있다. 범주형 데이터와 수치형 데이터를 구분하는 간단한 방법으로는 수치의 배수가 실제 값의 배수가 되는지 확인하면 된다. 월로 예를 들면 3월은 1월 * 3의 값이 아니기 때문에 범주형 데이터에 속한다.
수치형 데이터는 정량적 데이터를 의미한다. 수치형 데이터 중 이산형 데이터는 딱 떨어지는 값을 가지는 데이터이다. 범주형 데이터 중 연속형 데이터는 연속으로 이어지는 값을 가지는 데이터를 의미한다. 예를 들어 내가 75.12kg이라 할 때, 나는 실제로는 75.1231234123...kg일 수 있다. 단지 사람의 정밀도가 75kg인 것일 뿐이다. 이와 같이 자연에서 측정한 대부분의 데이터는 연속형 데이터이다.
우리가 AI를 다루고 모델을 개발할 때 사용하는 데이터는 대부분 수치형 데이터임에 유의하자.
3. 분석할 수 있는 데이터
데이터를 분석하여 AI 모델을 개발 할 때 어떠한 데이터가 있고 이것을 구분하는 것 뿐만 아니라 우리가 분석할 데이터의 구조를 알아보는 것 또한 중요하다. 기본적인 2차원 데이터 테이블의 예시를 보자.
| Lable | Feature 1 | Feature 2 | Feature 3 | Featuer 4 | Featuer 5 | ... | Featuer N |
열은 Label(혹은 Target 혹은 y)과 Fature(혹은 input 혹은 X)들로 구성되어있다. 각각의 행은 관측치 데이터를 의미하는데, 행은 분석단위이다. 즉 주가예측을 한다고 가정했을 때, 데이터 테이블의 Label이 일 단위인지, 시간 단위인지, 분 단위인지 파악하여 데이터를 어떻게 분석하는지 알 수 있다.
이것은 단지 2차원에서 머무르는 것이 아니다. 간단한 이미지나 자연어처리는 3차원으로 모델링한다. 이때 각각의 분석 단위인 이미지와 시계열 데이터가 2차원이기 때문인데 모델링은 (분석단위의 차원 + 1)차원의 데이터를 사용해야 한다.
4. NumPy
이러한 데이터를 다루는데 있어서 List는 한계점이 있다. 데이터 분석은 단순히 값의 집합 개념을 넘어서 수학적 계산이 가능해야하고 처리 속도가 빨라야하기 때문이다. 따라서 데이터를 분석하고 AI를 모델링할 때는 NumPy의 Array를 사용한다.

5. 라이브러리 불러오기
먼저 numpy 라이브러리를 불러와 사용해야한다.
import numpy as np
a = np.array([1, 2, 3, 4, 5])
6. 배열 만들기
배열을 만들기 전 먼저 간단한 용어 정리를 할 필요가 있다.
- Axis: 배열의 각 축
- Rank: 축의 개수 (차원)
- Shape: 배열의 형태 (각 축의 길이)
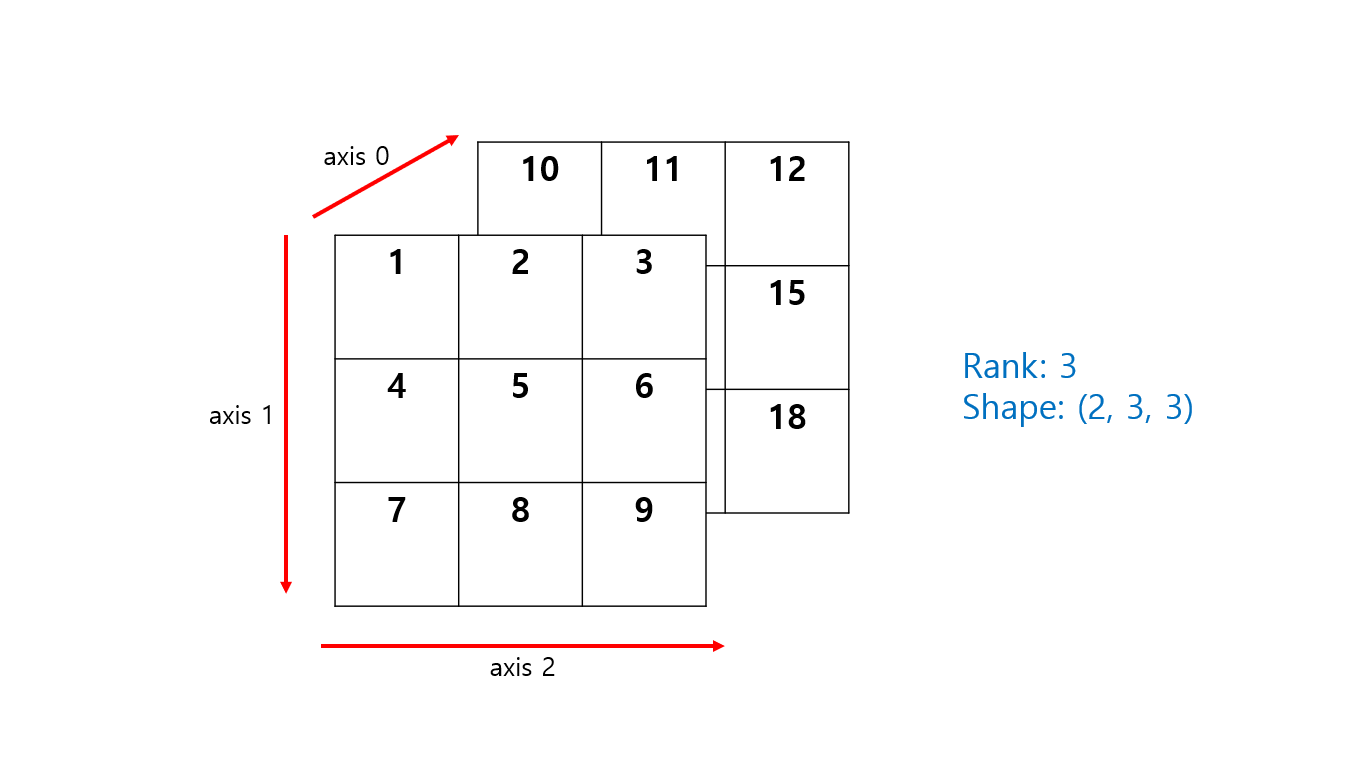
NumPy 배열를 만드는 방법은 다음과 같다.
# 배열 만들기
a = np.array([[[1, 2, 3], [4, 5, 6], [7, 8, 9]], [[10, 11, 12], [13, 14, 15], [16, 17, 18]]])
print(a.ndim) # 3
print(a.shape) # (2, 3, 3)
print(a.dtype) # int 32추가적으로 NumPy 배열이 제공하는 ndim을 통해 차원의 개수를 shape를 통해 배열의 모양을, dtype을 통해 배열 내부 데이터들의 타입을 알 수 있다.
NumPy에서 제공하는 reshape를 통해 기존 배열을 새로운 형태의 배열로 다시 구성하는 것 또한 가능하다. 이때 배열 요소의 형태가 사라지지 않는 형태라면 자유롭게 변환이 가능한데 방법은 다음과 같다.
a = np.array([[1, 2, 3], [4, 5, 6]]) # 2x3 형태의 배열
b = np.reshape(a, (6, 1)) # np.reshape(기존배열, 바꿀 형태)
c = a.reshape((3, 2)) # 기존배열.reshape(바꿀 형태)
d = a.reshape(3, -1) # a를 3행으로 된 배열로 바꾸는 코드이다. 자동으로 3x2 형태의 배열로 변경한다.
# e = a.reshape(4, -1) # Error! 배열요소가 사라지는 형태라면 에러가 발생한다.추가적으로 특정 배열을 만드는 여러 함수들이 존재한다. 방법은 다음과 같다.
# 0으로 채워진 배열 생성
a = np.zeros((2, 2))
print(a)
# [[ 0. 0.]
# [ 0. 0.]]
# 1로 채워진 배열 생성
b = np.ones((1, 2))
print(b)
# [[ 1. 1.]]
# 특정 값으로 채워진 배열 생성
c = np.full((2, 2), 7)
print(c)
# [[ 7. 7.]
# [ 7. 7.]]
# 2x2 단위 행렬 생성
d = np.eye(2)
print(d)
# [[ 1. 0.]
# [ 0. 1.]]
# 랜덤값으로 채운 배열 생성
e = np.random.random((2, 2))
print(e)
# [[ 0.31310012 0.58412893]
# [ 0.61807553 0.68816032]]
7. 배열 데이터 조회하기
NumPy를 통해 데이터를 조회하는 방법은 조건을 통한 조회와 인덱싱을 통한 조회가 있다. 먼저 조건을 통한 배열 조회 과정은 다음과 같다. NumPy 배열에 대해 조건을 주면 배열의 값을 하나하나 조건에 대입하여 Boolean 형식의 배열을 만들어낸다. 이후 Boolean 형식의 배열을 기존 배열에 집어넣음으로 배열은 조건을 만족하는 값만 들어있는 배열을 보여준다.
score = np.array([78, 91, 84, 89, 93, 65])
print(score >= 90) # [False True False False True False]
print(score[score >= 90]) # [91 93]다음으로 인덱싱을 통한 배열 조회 과정은 다음과 같다. 특히 배열[[행1, 행2, ...], [열1, 열2, ...]]과 같은 코드는 새로웠기 때문에 잘 기억해두는게 좋을 것 같다.
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = a[1, 1] # 배열[행, 열]
print(b)
# 5
c = a[[0, 1, 0], [0, 1, 2]] # 배열[[행1, 행2, ...], [열1, 열2, ...]]
print(c)
# [1 5 3]
d = a[[0, 2], :] # 배열[[행1, 행2, ...], :]
e = a[[0, 2]] # 또는 배열[[행1, 행2, ...]]
print(d)
# [[1 2 3]
# [7 8 9]]
print(e)
# [[1 2 3]
# [7 8 9]]
f = a[:, [0, 2]] # 배열[:, [열1, 열2, ...]]
print(f)
# [[1 3]
# [4 6]
# [7 9]]
g = a[1:3, 1:3] # 배열[행1:행N, 열1:열N]
print(g)
# [[5 6]
# [8 9]]
8. 배열 연산하기
NumPy 연산은 기본 연산들을 배웠다. (이번 수업의 목적은 데이터 분석을 하기 위한 준비이기 때문에 행렬곱과 같은 머신러닝을 위한 연산은 나중에 배운다고 하셨다.)
- 사칙연산
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
# 더하기 ( + 또는 np.add )
print(a + b)
# [[ 6 8]
# [10 12]]
# 빼기 ( - 또는 np.subtract )
print(a - b)
# [[-4 -4]
# [-4 -4]]
# 곱하기 ( * 또는 np.multiply )
print(a * b)
# [[ 5 12]
# [21 32]]
# 나누기 ( / 또는 np.divide )
print(a / b)
# [[0.2 0.33333333]
# [0.42857143 0.5 ]]
# 제곱 ( ** 또는 np.power )
print(a ** b)
# [[ 1 64]
# [ 2187 65536]]
# 제곱근 ( np.sqrt )
print(np.sqrt(a))
# [[1. 1.41421356]
# [1.73205081 2. ]]- 집계 함수
a = np.array([[1, 3, 2, 7], [3, 2, 9, 1], [4, 6, 8, 1]])
# 전체 합계
print(np.sum(a))
# 47
# 열 기준 합계
print(np.sum(a, axis=0))
# [ 8 11 19 9]
# 행 기준 합계
print(np.sum(a, axis=1))
# [13 15 19]- 조건에 따라 다른 값 지정하기 np.where
문법: np.where(조건문, 조건이 참일 때 값, 조건이 거짓일 때 값)
a = np.array([1, 3, 2, 7])
print(np.where(a > 2, 1, 0))
# [0 1 0 1]- 가장 큰(작은) 값의 인덱스 반환 np.argmax (np.argmin)
문법: np.argmax(배열, [axis=0 or 1])
a = np.array([[1, 5, 7], [2, 3, 8]])
# 전체 중에서 가장 큰 값의 인덱스
# 2차원임에도 1차원 형식으로 인덱스 반환
print(np.argmax(a))
# 5
# 열 기준 가장 큰 값의 인덱스
print(np.argmax(a, axis=0))
# [1 0 1]
# 행 기준 가장 큰 값의 인덱스
print(np.argmax(a, axis=1))
# [2 2]다음 게시글에서 이어서 pandas 라이브러리를 설명하도록 하겠다.
'[KT AIVLE School]' 카테고리의 다른 글
| 웹크롤링 # 2 Open API - 2022/08/03~2022/08/05 (0) | 2022.08.08 |
|---|---|
| 웹크롤링 # 1 동적 페이지 크롤링 - 2022/08/03~2022/08/05 (0) | 2022.08.07 |
| Python 라이브러리 # 2 pandas - 2022/08/01~2022/08/02 (0) | 2022.08.05 |
| 프로젝트 관리 도구(GIT) #2 - 2022/07/27 (0) | 2022.07.28 |
| 프로젝트 관리 도구(GIT) #1 - 2022/07/27 (0) | 2022.07.28 |



